Introduction
eta_x is the rolling horizon optimization module which combines the functionality of the other modules. It is based on the Farama gymnasium framework and utilizes algorithms and functions from the stable_baselines3 package. The eta_x module also contains some extensions for stable_baselines3, these include additional policies, extractors, schedules and agents.
The module contains functions meant to simplify the general process of creating rolling horizon optimization models. It contains the ETAx class which in turn combines all of this information such that you can start simple optimizations in just two lines. For example, to start the pendulum example (which is taken from the gymnasium framework):
experiment = ETAx(root_path, "pendulum_learning", overwrite, relpath_config=".")
experiment.learn("learning_series", "run1", reset=True)
experiment.play("learning_series", "run1")
The resulting optimization will have full configuration support, logging, support for multiple series of optimization runs and many other things.
Note
It is not necessary to use the ETAx class to utilize the other tools provided by this module. For example, you can utilize the functionality provided by Experiment configuration and Common Functions to build completely custom optimization scripts while still benefitting from centralized configuration, management of file paths, additional logging features and so on.
The algorithms in eta_x are an extension to the algorithms provided by stable_baselines3. These algorithms specifically include some algorithms which are not from the field of reinforcement learning but can be employed in generalized rolling horizon optimization settings.
The functions available in eta_utility.eta_x.envs make it easy to create new, custom environments (see stable_baselines3 custom environments). For example, they provide functionality for integrating FMU simulation models, communicating with real machinery in factories, or even integrating environments written in Julia.
The ETAx class is built on top of this functionality and extends the general Markov Decision Process by the option to introduce interactions between multiple environments. This enables the creation of digital twins, which could for example use a mathematical or a simulation model for some aspects and interact with the actual devices for other aspects as shown in the figure. Note, that this is only an option when using ETAx. The class also supports simple optimization of a single environment as shown in the code example above.
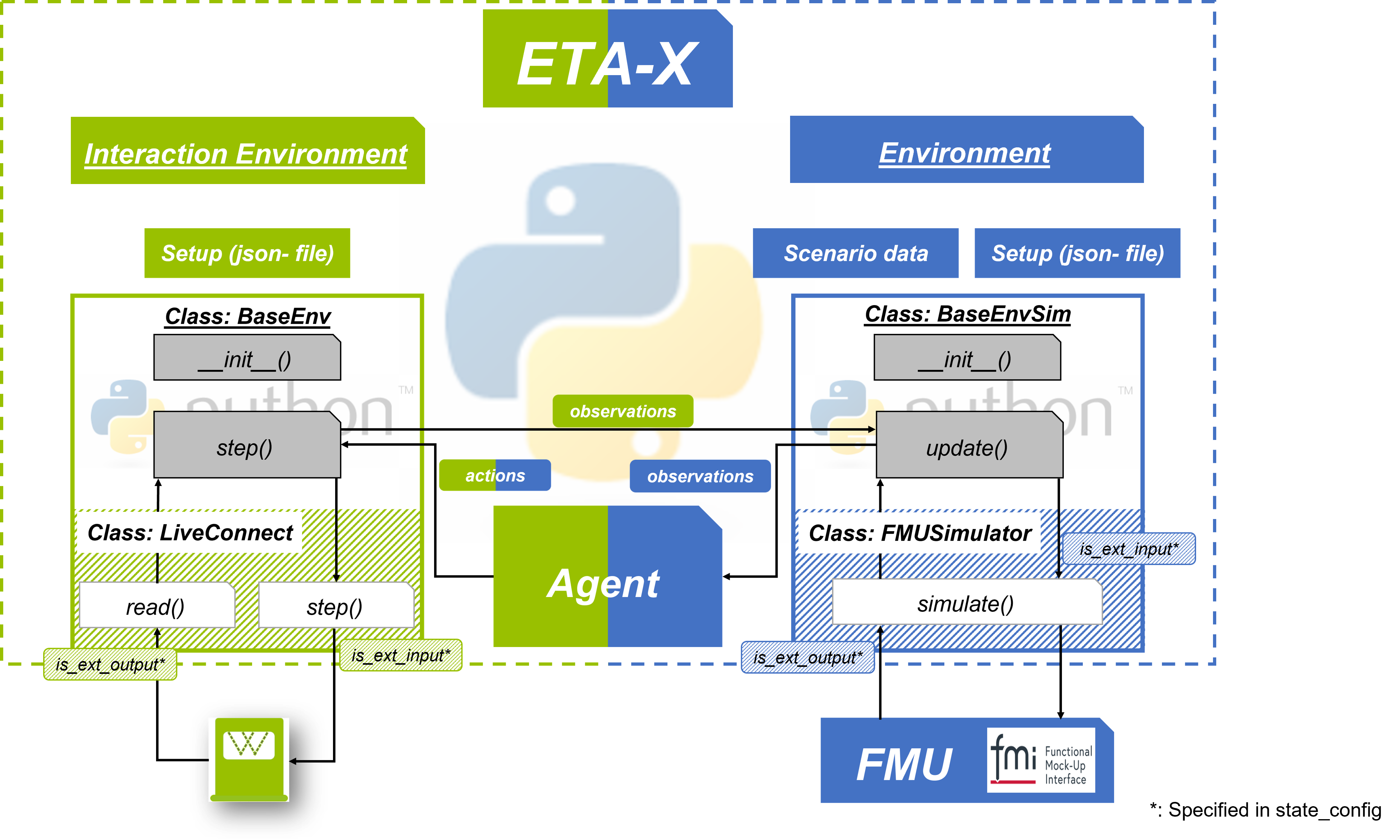
Example of an interaction between a real and a simulation environment.
The figure illustrates the entire process of environment interaction which consists of a step in the live/real environment and an update of the simulation environment before the agent receives the output of the simulation environment as its observations.
Take a look at the examples folder in the eta_utility repository to see some of the possibilities.
What are series and runs?
eta_x builds on the concept of experiments. An experiment can be configured to perform optimizations using specific environments and agents. An example of this concept is shown in the figure
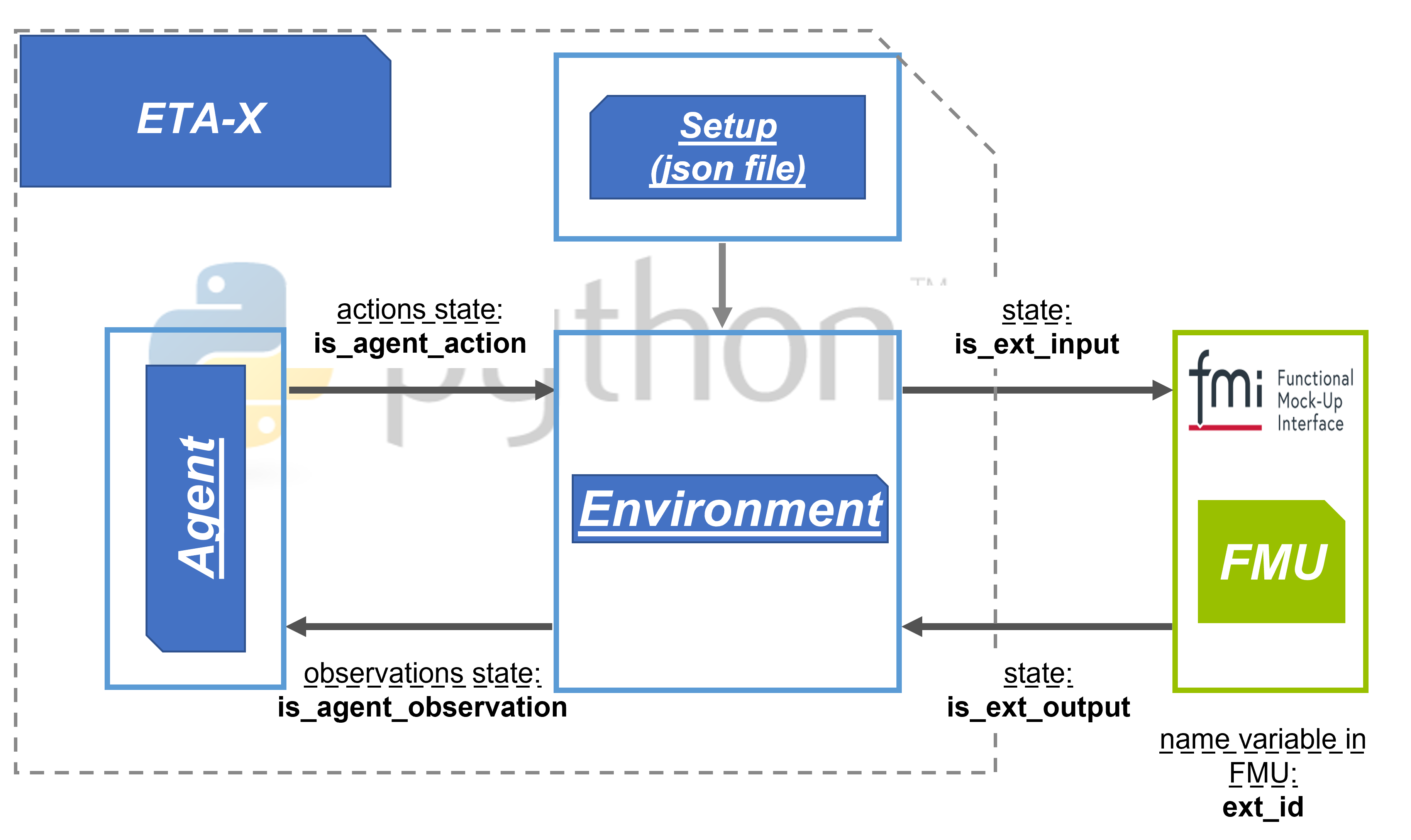
Example of the eta_x experiment concept.
As shown in the figure, the process starts with the configuration (setup) file, which is written in JSON format (see Experiment configuration). Based on this configuration, the environment and corresponding agent can be initialized and executed.
An experiment with a single configuration can consist of a series of different optimization runs. Each optimization run could for example have different external conditions for the environment (such as being performed at a different time of the year).
What is an algorithm or agent?
The control algorithm receives inputs from the environment and follows a strategy to control a system. This strategy could be either rule based, determined by mathematical optimization, machine learning (reinforcement learning) or other methods, such as metaheuristics.
The agent receives observations from an environment and determines actions to control the environment based on those observations.
What is an environment?
The environment is a dynamic system, which receives inputs (actions) from the control algorithm. Observations made in the environment are passed to the agent.
How to get started
Usually you want to use the ETAx class as shown above to initialize your experiment. This will automatically load a JSON configuration file (see also :ref: etax_experiment_config). The file to load the configuration from is specified during class instantiation:
- class eta_utility.eta_x.ETAx(root_path: str | os.PathLike, config_name: str, config_overwrite: Mapping[str, Any] | None = None, relpath_config: str | os.PathLike = 'config/')[source]
Initialize an optimization model and provide interfaces for optimization, learning and execution (play).
- Parameters:
root_path – Root path of the eta_x application (the configuration will be interpreted relative to this).
config_name – Name of configuration .ini file in configuration directory (should be JSON format).
config_overwrite – Dictionary to overwrite selected configurations.
relpath_config – Relative path to configuration file, starting from root path.
After the class is instantiated, you can use the play and learn methods to execute the experiment:
- ETAx.learn(self, series_name: str | None = None, run_name: str | None = None, run_description: str = '', reset: bool = False, callbacks: MaybeCallback = None) None[source]
Start the learning job for an agent with the specified environment.
- Parameters:
series_name – Name for a series of runs.
run_name – Name for a specific run.
run_description – Description for a specific run.
reset – Indication whether possibly existing models should be reset. Learning will be continued if model exists and reset is false.
callbacks – Provide additional callbacks to send to the model.learn() call.
- ETAx.play(self, series_name: str | None = None, run_name: str | None = None, run_description: str = '') None[source]
Play with previously learned agent model in environment.
- Parameters:
series_name – Name for a series of runs.
run_name – Name for a specific run.
run_description – Description for a specific run.
Experiment configuration
The central part of the eta_x module is the experiment configuration. This configuration can be read from a JSON file and determines the setup of the entire experiment, including which agent and environment to load and how to set each one up. The configuration is defined by the ConfigOpt dataclass and its subsidiaries ConfigOptSetup and ConfigOptSettings.
When you are using ETAx (the class) the configuration will be read automatically.
Use eta_utility.eta_x::ConfigOpt.from_json() to read the configuration from a JSON file:
- ConfigOpt.from_json(file: Path, path_root: Path, overwrite: Mapping[str, Any] | None = None) ConfigOpt[source]
Configuration example
The following is the configuration for the pendulum example in this repository. It is relatively minimal in that it makes extensive use of the defaults defined in the ConfigOpt classes.
{
"setup": {
"environment_package": "examples.pendulum.pendulum",
"environment_class": "PendulumEnv",
"agent_package": "stable_baselines3.ppo",
"agent_class": "PPO",
"vectorizer_package": "stable_baselines3.common.vec_env",
"vectorizer_class": "SubprocVecEnv",
"policy_package": "stable_baselines3.ppo",
"policy_class": "MlpPolicy",
"tensorboard_log": true,
"monitor_wrapper": true,
"norm_wrapper_obs": true,
"norm_wrapper_reward": true,
"norm_wrapper_clip_obs": 10.0
},
"paths": {
"relpath_results": "results/"
},
"settings": {
"sampling_time": 0.05,
"episode_duration": 15,
"save_model_every_x_episodes": 100,
"n_episodes_learn": 1000,
"n_episodes_play": 5,
"n_environments": 4,
"seed": 321
},
"environment_specific": {
"scenario_time_begin": "2022-01-04 12:12",
"scenario_time_end": "2022-01-04 12:13",
"max_speed": 8,
"max_torque": 2.0,
"g": 10,
"mass": 1,
"length": 1
},
"agent_specific": {
"gamma": 0.99,
"n_steps": 256,
"ent_coef": 0.01,
"learning_rate": 0.00020,
"vf_coef": 0.5,
"max_grad_norm": 0.5,
"gae_lambda": 0.95,
"batch_size": 4,
"n_epochs": 4,
"clip_range": 0.2,
"policy_kwargs": {
"net_arch": [500, 400, 300]
}
}
}
Config section ‘setup’
The settings configured in the setup section are the following:
- class eta_utility.eta_x.ConfigOptSetup(*, agent_import: str, environment_import: str, interaction_env_import: str | None = None, vectorizer_import='stable_baselines3.common.vec_env.dummy_vec_env.DummyVecEnv', policy_import='eta_utility.eta_x.common.NoPolicy', monitor_wrapper=False, norm_wrapper_obs=False, norm_wrapper_reward=False, tensorboard_log=False)[source]
Configuration options as specified in the “setup” section of the configuration file.
- agent_import: str
Import description string for the agent class.
- agent_class: type[BaseAlgorithm]
Agent class (automatically determined from agent_import).
- environment_import: str
Import description string for the environment class.
- environment_class: type[BaseEnv]
Imported Environment class (automatically determined from environment_import).
- interaction_env_import: str | None
Import description string for the interaction environment (default: None).
- interaction_env_class: type[BaseEnv] | None
Interaction environment class (default: None) (automatically determined from interaction_env_import).
- vectorizer_import: str
Import description string for the environment vectorizer (default: stable_baselines3.common.vec_env.dummy_vec_env.DummyVecEnv).
- vectorizer_class: type[DummyVecEnv]
Environment vectorizer class (automatically determined from vectorizer_import).
- policy_import: str
Import description string for the policy class (default: eta_utility.eta_x.agents.common.NoPolicy).
- policy_class: type[BasePolicy]
Policy class (automatically determined from policy_import).
- monitor_wrapper: bool
Flag which is true if the environment should be wrapped for monitoring (default: False).
- norm_wrapper_obs: bool
Flag which is true if the observations should be normalized (default: False).
- norm_wrapper_reward: bool
Flag which is true if the rewards should be normalized (default: False).
- tensorboard_log: bool
Flag to enable tensorboard logging (default: False).
Config section ‘paths’
The paths section can contain the following relative paths:
Config section ‘settings’
The configuration options in the settings section are the following.
Note
The configuration options “environment_specific”, “interaction_env_specific” and “agent_specific” are separate sections on the top level. They are loaded into the settings object as dictionaries. To determine, which options are valid for these sections, please look at the arguments required for instantiation of the agent or environment. These arguments must be specified as parameters in the corresponding section.
- class eta_utility.eta_x.ConfigOptSettings(*, seed=None, verbose=2, n_environments=1, n_episodes_play=None, n_episodes_learn=None, interact_with_env=False, save_model_every_x_episodes=10, plot_interval=10, episode_duration, sampling_time, sim_steps_per_sample=None, scale_actions=None, round_actions=None, environment=NOTHING, interaction_env: dict[str, Any] | None = None, agent=NOTHING, log_to_file=True)[source]
-
- verbose: int
Logging verbosity of the framework (default: 2).
- n_environments: int
Number of vectorized environments to instantiate (if not using DummyVecEnv) (default: 1).
- n_episodes_play: int | None
Number of episodes to execute when the agent is playing (default: None).
- n_episodes_learn: int | None
Number of episodes to execute when the agent is learning (default: None).
- interact_with_env: bool
Flag to determine whether the interaction env is used or not (default: False).
- save_model_every_x_episodes: int
How often to save the model during training (default: 10 - after every ten episodes).
- plot_interval: int
How many episodes to pass between each render call (default: 10 - after every ten episodes).
- episode_duration: float
Duration of an episode in seconds (can be a float value).
- sampling_time: float
Duration between time samples in seconds (can be a float value).
- scale_actions: float | None
Multiplier for scaling the agent actions before passing them to the environment (especially useful with interaction environments) (default: None).
- round_actions: int | None
Number of digits to round actions to before passing them to the environment (especially useful with interaction environments) (default: None).
- interaction_env: dict[str, Any] | None
Settings dictionary for the interaction environment (default: None).
- log_to_file: bool
Flag which is true if the log output should be written to a file
Configuration for optimization runs
An optimization run must also be configured. This is done through the ConfigOptRun class. The
class uses the series name and run names for initialization. It provides facilities to
create the paths required for optimization and to store information about the environments.
Below, you can see the parameters that ConfigOptRun offers. Full documentation is in the API
docs: eta_utility.eta_x.config.ConfigOptRun.
Note
ETAx instantiates an object of this class automatically from the JSON configuration file. You do not need to specify any of the parameters listed here. They are listed here to show what is available for use during the optimization run.
- class eta_utility.eta_x.ConfigOptRun(*, series: str, name: str, description, path_root: Path, path_results: Path, path_scenarios: Path | None = None)[source]
Configuration for an optimization run, including the series and run names descriptions and paths for the run.
- series: str
Name of the series of optimization runs.
- name: str
Name of an optimization run.
- description: str
Description of an optimization run.
- path_root: pathlib.Path
Root path of the framework run.
- path_results: pathlib.Path
Path to results of the optimization run.
- path_scenarios: pathlib.Path | None
Path to scenarios used for the optimization run.
- path_series_results: pathlib.Path
Path for the results of the series of optimization runs.
- path_run_model: pathlib.Path
Path to the model of the optimization run.
- path_run_info: pathlib.Path
Path to information about the optimization run.
- path_run_monitor: pathlib.Path
Path to the monitoring information about the optimization run.
- path_vec_normalize: pathlib.Path
Path to the normalization wrapper information.
- path_net_arch: pathlib.Path
Path to the neural network architecture file.
- path_log_output: pathlib.Path
Path to the log output file.